|
| Stephen Brooks 2012-03-20 17:13:12 | I don't seem to have written a post about this new lattice started on Friday. Evidence from previous 900MeV linac optimisations suggests the optimiser is finding different local maxima in muon yield on each run. There is a certain degree of randomness (or so it appears) in which maximum it ends up in, so running many optimisations in parallel may explore more options and end up with a higher result overall. The samplefiles system generally means that once a high peak has been found, the entire project congregates around it: the optimiser will naturally not choose to "ignore" high-yielding designs for an extended period, which is what is required to find a genuinely new local optimum. Later revisions of the optimiser may include "branching" systems to do this exploration when the current track appears to be exhausted. However, with the current client I can emulate many independent optimisers simply by switching off samplefiles for this particular lattice. This will have some interesting consequences for the Muon Yield % leader board for Linac900Ext6Xc2_nosample. Users will tend to be "sticky" in their position and having a faster CPU will benefit your muon yield more than usual since you will be able to progress faster up the optimisation landscape (instead of running with the whole group using the samplefile). Incidentally, you can seed this lattice with Linac900Ext6Xc2 results but I recommend against this, as this will just put you in the same local maximum as that optimisation ended up in, so you will likely do no useful work and may ultimately be overtaken by those exploring higher peaks. You will also likely see more diversity in the per-user Mpts-yield graph in this lattice. |
| Dave Peachey 2012-03-21 17:57:54 | Stephen, On side point, how is your recommendation against seeding the lattice affected by (what I presume must be) the Bionc Wrapper approach wherein a single instance of the Muon1 client is run for each download which (presumably) has a seed associated with it. I wonder about this impact by virture of the fact that the top 20 best percentages returned is currently weighted 75% towards Boinc Wrapper users with, on the whole (albeit not exclusively), fewer than 100 results returned per user; whereas the remaining 25% of the Top 20 have taken several thousand results to get there. Not that I'm complaining, just wondering how that impacts on your "no sample file" theory for this particular run and the results derived as a result. Dave [Edited by Dave Peachey at 2012-03-21 17:58:28] |
| Stephen Brooks 2012-03-21 18:01:39 | I've e-mailed the yoyo@home administrator asking about this. I thought they could store each user's results history persistently now. Ideally any sample file mechanism should be turned off for "_nosample" lattices. |
| Stephen Brooks 2012-03-21 20:39:00 | He has replied saying this has been implemented. |
| Stephen Brooks 2012-03-24 20:17:42 | Embarrassingly, the _nosample lattice now exceeds the yield of the other two lattices, which have been running for longer. On the other hand, only three users are above 0.6% and out of those, I know DanC has been manually modifying designs. I wonder if Tuinhuis and Maniacken have been doing the same? Manual modification isn't necessarily bad in this case, but it would help if I knew whose top yields were "natural" and whose are modified. |
| Dave Peachey 2012-03-24 21:30:12 | Well mine are all natural  |
| [DPC] Mr. Aldi 2012-03-24 21:38:24 | This new client is more accurate right? So it is not necessary anymore to do 5 runs on new best result? As there is no sample-file every client is going to do a lot of 5 times runs as it thinks it has found a break-through. By removing this 5 times recheck we would be able to scan 5 times faster  |
| Maniacken [US-Distributed] 2012-03-25 03:13:39 | My result is natural. |
| K`Tetch 2012-03-25 05:18:57 | Aldi - my understanding is that the 5 runs isn't for 'accuracy' (in so much as the jitter is gone) but accuracy as in repeatably, since it uses a fixed 'seed' design ('seed 0' which is one possible 'spread' of particles, and seeds 1-4 are extremes of that. The idea is that every 'best' design of every client (the coloured pin on viewresults history graph - H) does have a 5-run, thats the 'standard' for a successful design anyway. The rest only get one run because they're not worthy of full study. So you've kinda got it backwards. It's SUPPOSED to have a 5-run, but those which don't make the cut the first run, are cut short (Of course, all of this based on half-remembered conversations from Stephen from 5-6 years ago) |
| Zerberus 2012-03-25 10:13:20 | Needless to say, if you set it to less than five checks, the result won't generate a checksum and thus won't be counted. |
| [DPC] Mr. Aldi 2012-03-25 16:20:39 | @K'Tetch, Thanks for explanation. I see that yield still differs with each seed. So accuracy and the recheck are different things. Still, as the sample file now would already contain a 3.5% design, my resuls.dat also would contain such a high yield design, thus avoiding rechecks untill it found a new best design. Now my computer is continuously rechecking lousy 0,3% yield designs, which in my view is wasted time and energy... The percentage of results that got rechecked with lattice_nosample will be higher with a lattice which uses a sample-file. @Zeberus, indeed. |
| Stephen Brooks 2012-03-26 15:02:58 | You could set the rechecks to 1, let the optimiser zip ahead with the less accurate (and not submittable) results and then turn them back to 5. But the 5 rechecks are in there for a good reason: to ensure the top results have higher statistical accuracy, whether that's within the whole project or your personal results database. Turning it off means your optimiser is working from less-accurate top results. |
| K`Tetch 2012-03-26 21:14:23 | Sure, Aldi, there's a 3.5 out there already. BUT, what we don't know, and what the aim of this lattice is, is to give some breadth. At present, the samplefiles mean most clients focus on whatever the best result or two. You're going to focus on whatever the best design is, but that may not be the best design POSSIBLE. Or, put another way, it's like watching 8yos play football - everyone keeps runnign after the ball. If that 3.5% is Mount Blanc, then you chasing afterf it means you're going to be running all over the alps trying to find the highest mountain, and never come CLOSE to Everest, unless one of the rare random's hits on the general area. The point of this lattice, is to see about independant design, compared to the collaborative design of the past ones, and it's already done better than most other lattices of this design batch, in just a week or two. I feel your pain, I do. I see you've done 202 results and are at -0.360041. My laptop has done 1600 results on this lattice, and only just gone positive in the last 20 minutes. The last 1000 results have been stuck at -0.15 to -0.13. Your team mate, Xanathorn, has done almost 17000 results (more than anyone else), and has yet to go positive. In fact, the next person to have done so many, is DanC, who has done half as many, but has the 3.3% result you mentioned. My desktop, ont he other hand (which is about 30% slower, mainly because of ddr2 ram v ddr3) has been positive for a week, BUT getting results which are 0.4% with 1500MPTS. A 5-run on that takes 5 hours. The fact is, there are 10^282 design possibilties. Muon1 only works well when it can cut that number down efficiently. As it was, a month ago, it wasn't. When the 9Xc2 and 7Xc2's were launched, Stephen posted a table of Ext series results. The d2 designs were at the bottom, the c2 designs were at the top, and the single-phase was in the middle (t means extended time, and X means extended time and 4.45 only, which also has a slightly lower yield) but they're the exact same design space, Ext6d2 got 1.43% and Ext6tc2 got 4.38%, but they both have the same theoretical designs available to them. The difference is the way the RF phase was represented. That was an indication of an optimiser problem. I do think it's kinda funny about how this project has some people worrying about yields, when other projects don't have anything like it. With RC5 you get the ONE key, or you don't, seti@home, you either get to be jodie Foster, or not, and it's the work done that matters. So for now, maybe focusing on the work done, rather than the yield percentage might be best, just like you would with any other project. And remember this, there's still the possibility that there's a magic combintion of design factors, that if slightly out gives -0.3's but when it hits that narrow window, gives 17% yields.... Not so much a mountain, but a space elevator. |
| Stephen Brooks 2012-03-27 17:50:36 | @Mr. Aldi - don't worry about the low yields, you're a long way "below" DanC but you may also be somewhere sideways of him, with a higher peak above. This lattice is like doing 100 individual lattices (one for each user), which will take longer but give more chance of reaching a very high yield. |
| [DPC] Mr. Aldi 2012-03-27 18:18:28 | Thanks for your extensive reply! Lol @ Foster. Indeed everybody is focused on the yield. I see the value of fully concentrating on crappy designs of which maybe one is that Ronaldo But we only have to check once to see whether it is a Ronaldo or just another kid without a clue. Recheck on 3%+ designs I understand. Rechecks on just positive designs, not so much. As long as each 1 recheck out of 5 only vary with few hunderth of the yield %. Let's search for this magic combination! I also think this result (lattices are the same?) is worth checking further: http://stephenbrooks.org/muon1/plots/graph1/?optim=Linac900Ext6Xc2&coords=?1043,221 @Stephen, to reduce some 5 times runs in the start I can use this trick with less particles indeed to get above 0%. But after that every minor improve will still be rechecked 5 times |
| Stephen Brooks 2012-03-28 15:27:05 | I still want lower-yield results to be rechecked 5 times because although they're not the best overall, they are the best in your branch. Often Muon1 wants to distinguish between quite close competing designs near the best yield, so to do this it needs as much statistical accuracy as possible. Also, if you have a computer error on one result that gives a very high yield, the recheck mechanism will prevent that from completely skewing your results. |
| Hannibal 2012-03-28 18:33:20 | @Stephen If you are getting a lot of 5x rechecks, that means your designs must be improving. If this is true, thats OK, but it isn't. Muon save in results file some kind of average value of all runs. Sometimes (when near maximum, most of times!), first result is better than best so far, but average is lower. For local best check, only value form same seed should be taken. I understand, you can be skeptical to this, but you could do an experiment. You can made new muon version, where recheck count and which result is save, are defined in lattice file. And next run identical simulation in 3 versions: 5 recheck with average saved, 5 recheck witch first saved and no recheck. [Edited by Hannibal at 2012-03-28 18:34:26] |
| Stephen Brooks 2012-03-28 21:05:26 | Yes, it will also recheck values very near the maximum, so what I said wasn't strictly true. But it is important to recheck values near the maximum to find out (accurately) whether they are better or not. (From the point of view of Mpts, rechecked runs are worth 5x what a normal run is, so you don't lose Mpts score because of this). |
| Hannibal 2012-03-28 23:31:42 | My english is to bad to explain what I mean. Maybe example helps. Let best muon so far is 1.00 and have next following results: Bold values are counted score, normal not counted but show as it was counted.
Row 1 - It is best and is rechecked - this is OK Row 2 - It 1 score is worse than 1 avg, so it isn't rechecked - but it is possibly better than 1 - lose for project. Row 4 - It 1 score is better than 1 avg, so it is rechecked and run 4 times more, but in the end it occurs that it avg is worse than 1 avg - so we have 4 not necessary runs - lose for project. In final stages it heavy dominated others by meaning of CPU time. So my conclusion is that ONLY first result should be saved as best, or at least only it should be used as threshold for recheck. Other should be used only for proof that first one is not mistake by counting "standard deviation" or other statistical method. This allow check much more of search space instead of proving that some individual design is in fact 0.02% worse o better. I can mistaken, but experiment I suggested in previous post, can show us which approach is better, and more profitable. |
| Stephen Brooks 2012-03-29 10:43:21 | The optimiser will tend to focus on the result in your history (results.dat) with the highest score. So it's important that the highest result is *always* rechecked, which effectively means 3-5 times as many particles are used for calculating it. Any mechanism that allows single runs will sometimes miss a result that would be better on a rechecked run (the only way to fix that would be to recheck everything). |
| Hannibal 2012-03-29 14:15:25 | We still misunderstanding. I don't tell to do not recheck at all, but do this little smarter. As a threshold for recheck new result should be taken ALWAYS first results, no matter how average for 5 run was. Only lower results with big standard deviation should by throw away. This is probably no better in per run point of view - both current and my method miss some better designs. But in CPU time point of view my proposal is better as is will reduce number of not necessary rechecks significantly. If you save per user results timeline, you could check chow MUCH time is wasted to recheck "no better" designs. In my method will be no such rechecks. If new first result is better than previous first results, and standard deviation is OK it will be always used as next best results. I hope this time, I wrote clean enough. |
| Stephen Brooks 2012-03-29 14:29:16 | --[As a threshold for recheck new result should be taken ALWAYS first results, no matter how average for 5 run was.]-- But how do I know what the average of the 5 runs will be if I have only run the first result? --[Only lower results with big standard deviation should by throw away.]-- Muon1 does not "throw away" results. They do not "fail" recheck, it is simply that some are rechecked (giving 5x the particle statistics) and some are not. --[If new first result is better than previous first results, and standard deviation is OK it will be always used as next best results.]-- A single result on its own should not be used as the "best" result at any stage. I prefer that the highest-scoring result that the optimiser sees is always run 5 times. |
| K`Tetch 2012-03-29 15:06:50 | Perhaps it's because things are being looked at the wrong way. Hannibal, you're under the impression that the 1x run is 'normal' and the 5x is 'more work'. Instead think of it this way. The 5x is normal. Every best result has had a 5x run, and that's how it's designed to be. the 1x runs are shortcuts, because they're worse designs. Now, seed0 (the first run of a design) is now usually 'slightly above final result yield'. Thus initiating the 5x run giving a 'proper' result. This project isn't just about 'who can climb and get the fastest yield, it's a scientific project, and thus needs to be scientifically accurate. |
| Hannibal 2012-03-29 16:42:36 | Unecessery 5 runs is a waste. Finding best results should be as fast as possible. The recheck, if required, can be done later by some designated computers. But I have solution to always have best score rechecked, without additional computing stage, with speedup of my idea. We can make 5 ways optimization. W choose random seed (one of our 5), a the beginning and run simulation. We make recheck only within results form this seed. If it is better we make recheck otherwise not. If we found (during recheck) in some other seed results better than others in that seed, we already have it rechecked! So we have all best results rechecked, and w didn't run wasteful, in my point of view, checks. |
| Stephen Brooks 2012-03-29 16:51:34 | If you want, you could use the -/10 switch to run with 10 times fewer particles. That would be a lot faster for a "rough" optimisation, but might not see detailed effects because the individual result scores would be less accurate (that's why the project won't give checksums for those results). You'll probably see faster optimisation to begin with but maybe getting stuck later on. The rechecks are not wasted effort: they increase the effective number of particles simulated by between 3 and 5 times (the particle distribution is different in each recheck), so the statistical error of a rechecked score should be about half that of a single run. The recheck mechanism gives protection against single-result computer errors as a bonus, but that's not the only reason we do it. |
| Hannibal 2012-03-29 17:58:55 | All the times, I have feel you don't understood me properly  I don't complain about rechecks at whole, but only for run them far to often. There are simulations that after first run I know it won't be better after recheck. Such runs are: 1. Waste of time, which can be used to check some other design and have better coverage of search space. 2. Frustrating for user, especially when sim is 2500Mps long. In my primary ~600Mps/h (when idle) computer, it take at least 17 hours to recheck. Far to much, when I'm almost sure it won't be better... So because of that, I suggested solution for this "problem". My first idea, won't satisfy your requirement to be all best designs rechecked, but second does. It eliminates flaw of current design were value from FIRST run are compared with AVERAGE of best. This values mean in fact something different and REALLY SHOULDN'T be compared in this place. IMHO only comparing results from one seed should be done, as only this is reliable. Effects of this comparing, I try describe in all my posts. Additionally, this "evil compare" can also affect optimizer when results with both 1 and 5 runs are taken to generate new designs. They can pull design in different ways, causing stuck somewhere in between, degrading "optimizing" performance even more. |
| Stephen Brooks 2012-03-29 18:21:01 | You're assuming that the first result being higher (or lower) always means the average will be higher (or lower). That often is the case, but it is not guaranteed! So you can't reliably use the first result to tell if a new design will be the "best" or not. Also, your computer is not the fastest, so maybe you could set config.txt to only use the 7Xc2 and 9Xc2 lattices with samplefiles? "_nosample" lattices will be very unforgiving to slower computers! |
| Hannibal 2012-03-29 18:51:47 | --[You're assuming that the first result being higher...]-- No, I'm not assuming that. I'm only mean that if first it is close enough to "real avg results" we can take this "first" as best without significant impact for project. In fact, as we eliminate "additional unnecessary recheck", and run more simulations, we can get better result overall. And this is true only for my first idea. In second we always have best average, despite fact we didn't optimize it directly, but by all seeds independent. As I think you are get closer to what I mean in my first idea. You can think about second as of concatenation of 5 "first ideas" with different first seed and shared rechecks. --[Also, your computer is not the fastest...]-- My computer isn't real issue here. If we improve way we test designs, all of us will be profitable. Only owners of slower computers little more - as they have bigger chance to have best design [Edited by Hannibal at 2012-03-29 19:05:46] |
| K`Tetch 2012-03-30 02:31:39 | I think we're getting a little confused here, Hannibal. You're believing that the first run (seed 0) is a representative setup. It's not. It's 1/5 of what's needed. To save time, that's all that's run, most of the time. When it gets close to the known maximum. Maybe this will help illustrate things This is frmo the high-resolution (3x the particle count) scan pass done 18 months ago, and was used in testing 4.44d and what became 4.45 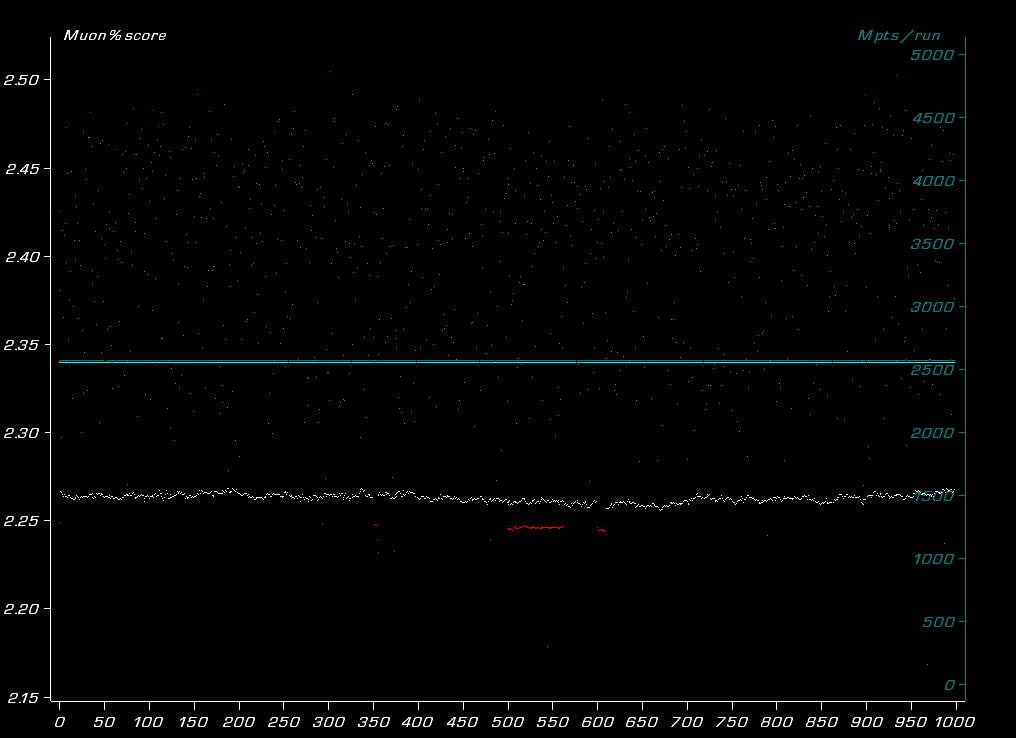 You see the solid white line, thats 4.45. the random dots, thats 4.44d running the same results (this is all with just one variable changed as we went along the x axis. You'll notice a red line and random faint red dots too. Those are 5x runs. The line is from 4.45 and the faint dots are 4.44d. You can see the difference (by the way, the 4.45 run were given the highest yield from the 4.44d runs, which is why only one batch did the 5x run) Now, that was an irrelevent parameter being varied from 0-1000, but when it's one that matters, we get this graph 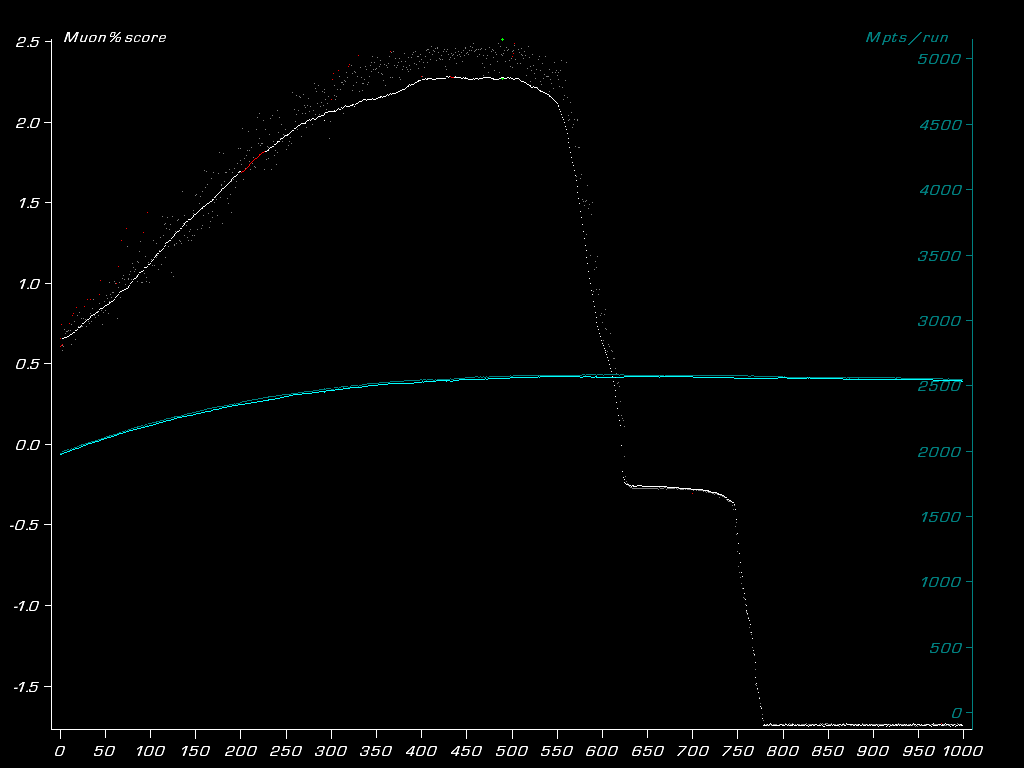 Save conventions. You'll notice the 4.45 red line is pretty much in line with the whites, that's what we have now. You'll note the red section top left, that is a drop from the white 1x at the start but by the end it's slightly above. That's what we're talking about. Finally, this lattice is all about working on the optomiser. Right now, sometimes needless 5x runs are the least of the worry. look at this chart  The recent lattices are coloured by block number. SEe how they all end at different points? Same colours should end at the same points, and ideally, they all end at the exact same point. The actual design parameters haven't changed between them, but the ways of 'describing' the designs have. (in theory you should be able to design the same particle accelerator in each lattice, even if every value is 999 or 000) This means we're getting stuck on local maximums, and 1x or 5x doesn't matter if you're stuck in the same area (we're already way past the best design for 6d2, despite over 634,000 simulations spanning 334 Million MPTS. Sure we can have a lot of results, but a lot of crap 'rushed' results aren't that useful. Then someone (like stephen, or me) has to spend time running them again, so we've lost time, because we've spent the CPU power you would have done running them in full the first time, PLUS there's the cpu time you spent doing your quick run. |
| Hannibal 2012-03-30 06:10:29 | OK - you prove me, that my first idea was not good. But your arguments doesn't point my second idea. Yes, it will optimize individual seed alone, which is not good as you say. But we since optimize all 5 we have no chance to miss something. If you tell that is waste of time - you wrong. Rechecks from individual seed contain results for all other seeds. So if we found something great in one seed optimization line, we automatically pull up others seed optimization line - no time waste. And when you look closely, all best results always have 5 runs. This method remove "evil compare" between average and single seed results - which I wan't. And keep top results always 5 times rechecked - which you want. |
| Hannibal 2012-03-30 21:03:37 | Here is sample random results that can be generated in my second method. Bold values are new result generated in that run. Red values are new best in seed. Parameters used to generate - there are optimistic to demonstrate my metod: 100 runs (without rechecks) 75% - to generate worse result 20% - to generate result better less than 0.1 5% - to generate result better less than 0.2 +- 0.1 spread around rechecked value
Sorry for long spoiler - but I cannot remove it .[Edited by Hannibal at 2012-03-30 21:12:06] |
| Hannibal 2012-03-30 21:15:51 | PHP Source code used to generate table above. You could alter parameters to match project, and check if my second method i worth of try. I will not write about it any more, if I'm not asked.
[Edited by Hannibal at 2012-03-30 21:23:53] |
 0, $newval - 0.1), $newval + 0.1);
0, $newval - 0.1), $newval + 0.1);| AySz88 2012-04-24 05:06:34 | Hmm, this conversation with Hannibal makes me wonder if it's possible to calculate an uncertainty in the result, using an explicit statistical model and/or bootstrapping? Then the program might be able to go about things much more cleverly. A rule could be, for example: do a recheck iff (1) the new design has not been excluded from being optimal with more than 95% confidence, and also (2) the standard error of the new estimate has not fallen below some set number (to limit rechecking). I've done something a little like that second part for a perception experiment at work, where there's human subjects and we don't really want to waste their time showing the same stimuli over and over if the statistical model is already confident in a result. [Edited by AySz88 at 2012-04-24 05:22:20] |
| Hannibal 2012-05-08 23:13:37 | I say, I don't say nothing more not asked - shame on me... But I have some more accurate and scientific information, so maybe you forgive me I was able to simulate my way of optimization by mixing some changes in config.txt, lattice file and external higher level management program (simple and crude but good enough). Till now I had run 3000 individual seed simulations of "Linac900Ext6Xc2_nosample". 99 of them was rechecked - so this give ~2600 designs tested in point of view current way of optimizations. Best "best individual seed" is now -0,105945, worse "best individual seed" is -0,138444 and best average of rechecked results is -0,130794. If someone is interested in any kind of data connected with my experiment, I may provide it to him/her. This can be: changes I provide to config and lattice files, source code (C) of management app (or linux binary), individual results.dat form each seed, management program log showing order of results at whole. Additionally, because I have individual seed results, I make some simple statistical analysis which I can also provide (Libre Office Calc ods file). I'm intended to run this experiment for some more time. I hope, I brake 0.0000 muon percentage soon and show strength of my method. |
| K`Tetch 2012-05-09 00:06:38 | I've got 4 separate 'strains' going. I think only ONE took over 2000 results to go positive.... |
| Hannibal 2012-05-09 16:27:26 | Near 3100 first seed broke 0 boundary. Near 3600 all of them do this. So is no so bad. You must also noted that "below zero" and "above zero" are in fact entirely different projects. Below zero muon percentage is chosen by you to evaluate designs that didn't ends with single muon with desired energy. My statistical analysis show that this method is far from perfect (VERY chaotic). One of rechecked results have standard deviation 0.202693! and be super flat in next recheck (0.005808 std. dev.). Even few positive rechecks, my experiment runs so far, shows that positive site of 0 behave much better. Std. dev. is noticeable ~0.03-0.04, but there are no peaks. So my method should works better now. |
| Hannibal 2012-05-21 18:33:48 | Now I had run above 10k single seed simulations. I'm not happy with results it have achieve. The average is barely exceed 0.2%. It have stuck in some local maximum; practical not real - I will explain what I mean in some later post along with conclusions. But, first I will 1-2k simulations more - because I have some signs of breakthrough. For interested here there are: Text file with results of each run indicating also seed number and if this recheck run. Libre Office Calc spreadsheet with rechecked results, and some statistical computations on it with charts. |
| K`Tetch 2012-05-21 22:23:01 | " It have stuck in some local maximum" And that's the entire point of this lattice. In the past, we've had 80-90% of users run the samplefiles, which were updated every 4 hours, I believe. That meant that a new best result came in, and within 12 hours, 80% of the users had that in their local samplefile, and were using it to develop a new design. SO now the majority are congregating around it. That's fine if that's the best design path overall, but if not, then everyone's focusing on a less good area. Then it's left for the handful not running the samplefile to eventually come up with a design that's better. Everyone huddles around what's the best design at that moment, regardless of the long term consequences. It's one reason I convinced Stephen to run the samplefile only once a week, as it will help give some diversity, without everyone suddenly being distracted by the latest, best design like a 5yo with ADHD. Even moreso, that's why this lattice is being run. We're looking at totally independant design, and seeing how different clients take different threads. The lack of samplefiles helps because now we can hope that each user is one (or more!) seperate design paths.so we can get some idea of design growth. And it's kinda working, as you can see here 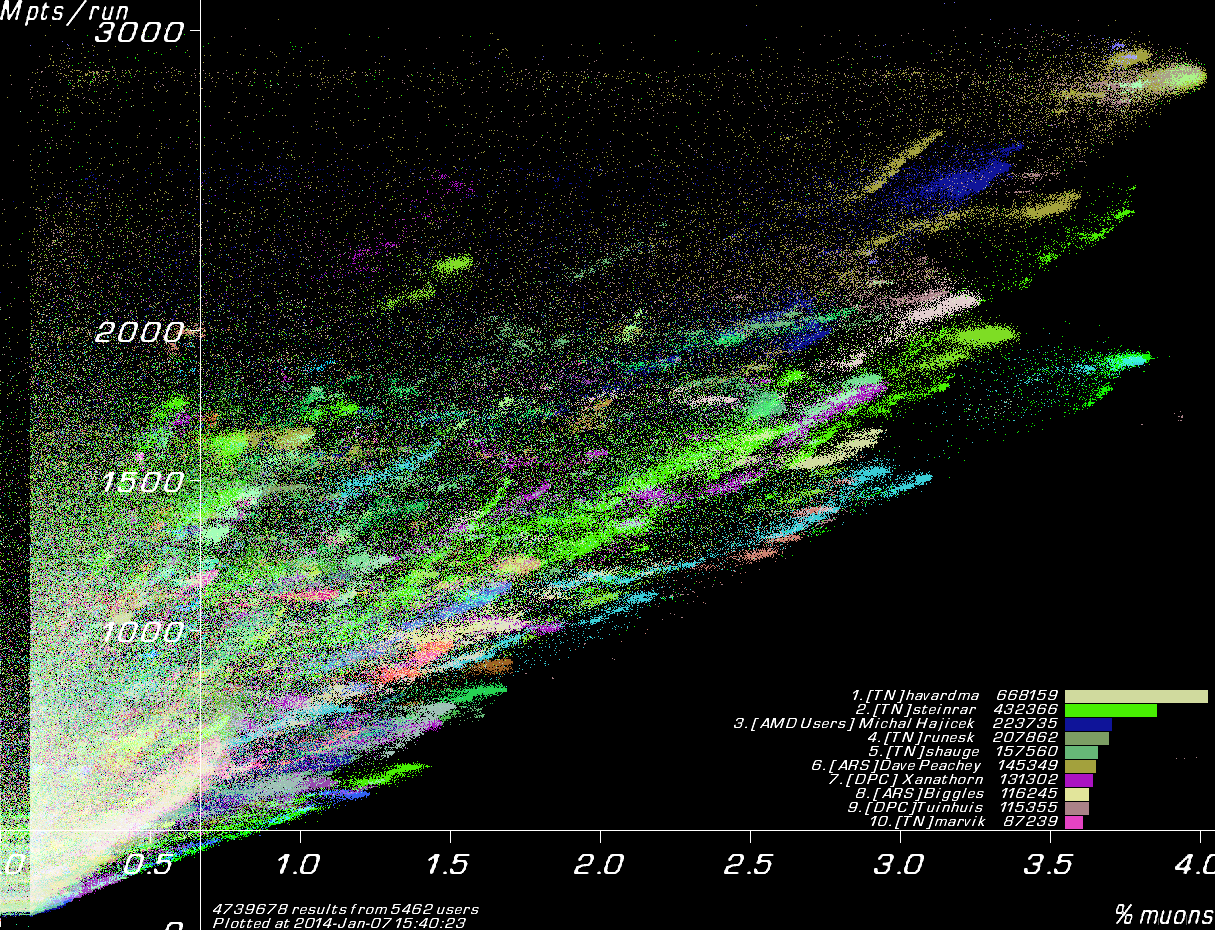 You can see my manual design train at the far right (I'm bright green) Contrast that with the far more homogeneous one when run WITH the samplefiles 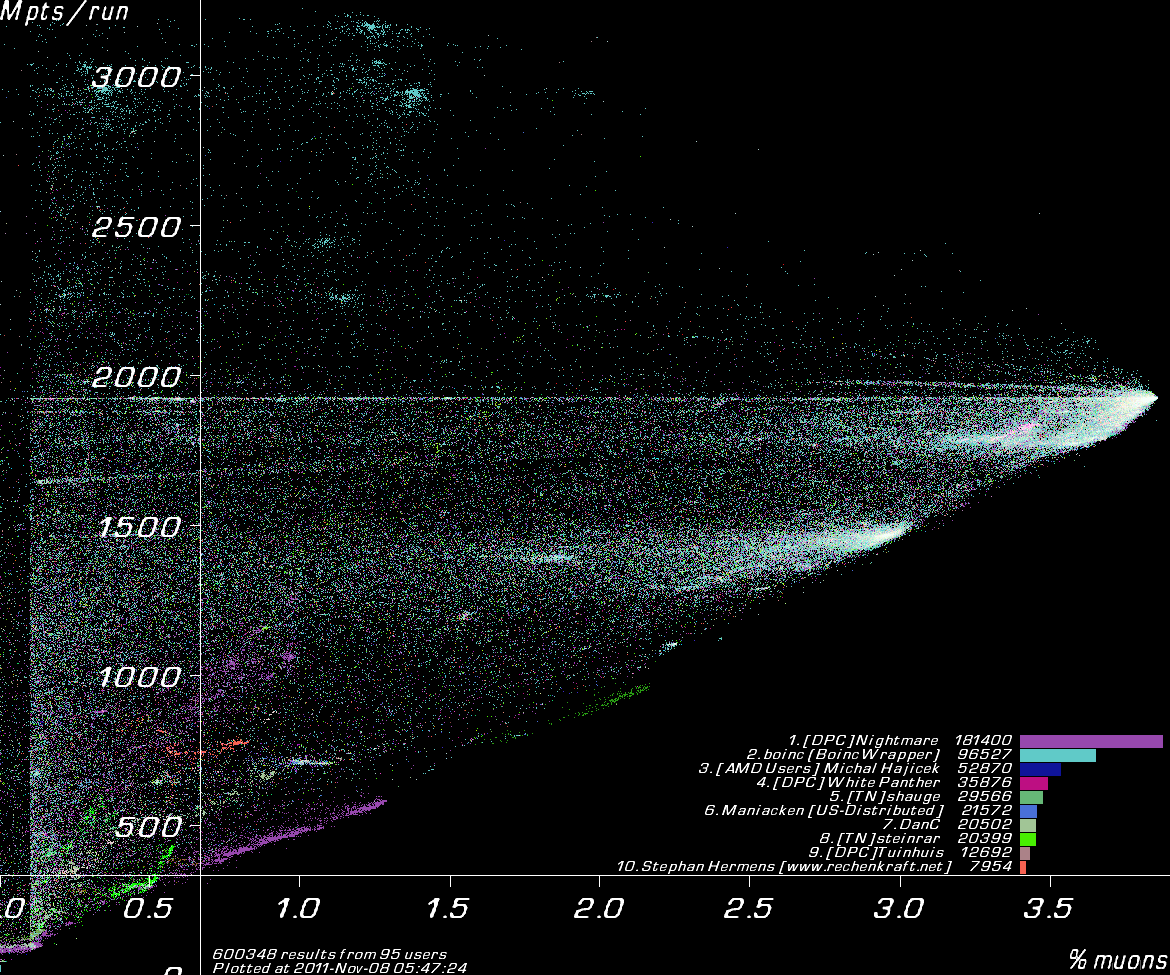 This second one has twice as many results, but you can see there's far fewer design paths taken, most have followed one particular path, and that's not good. So that's our current focus. I know you're focused more on recheck rates (or rather, full runs, rather than 1/5th runs) but we're worried about design optomisation as that's by far and away the most important. |
| Xanathorn 2012-05-22 00:22:59 | Took my client like 25000 results to get out of the negative, but last few days it's jumping forward slowly with a currently 1,7%. I just let it run though, no manual tweaks or something. Takes more time perhaps than with samplefiles, but like K'tetch said also more diversity instead of everyone computing the same optimisation train; which tends to get stuck at a certain percentage longer the higher it is. |
| K`Tetch 2012-05-22 01:03:12 | Yeah, I've been watching your results, Xanathorn Wish I had your computing power too (I have a q6600 and a i3-380m, which has spent the last 10 months being used for the best designs series) Also, thanks for getting K`Tetch right - most people forget the second T The point this time isn't to go for the best design. Those two images above, they're for EXACTLY the same lattice, the ONLY difference is that the bottom one had samplefiles, and the top one didn't I count at least 14 clear, different design paths in the nosamples chart, maybe 6 in the ones with samples. The difficult thing will be trying to get the group work of the samplefile stuff, but without losing the diversity, and getting stuck in a local maximum. My current thought (and since Stephen is at a conference in NOLA, I've not talked it over with him) is that if the client goes say 500 sims without an improvement, then it 'writes it off' as a local maximum, and doesn't use it for single-design mutations (using it for two-design ones like interpolation would be ok) The problem is identifying 'blood lines', and keeping track of derivatives. But perhaps a way to write off design paths as 'maxed out' might be the simplest way to do things, rather than a COMPLETE re-write of all the mutation code (I don't know though, I'm NOT a coder) And while I can't speak for Stephen, I'm sure hearing other people's broad ideas on how to avoid getting stuck in maximums might give us some thoughts (but be warned, you give up any rights to them ideas, and they may or may not be used etc. standard legal stuff etc. etc.) |
| Hannibal 2012-05-22 21:15:33 | You call me to answer little earlier I intend to. >> It have stuck in some local maximum >And that's the entire point of this lattice. In fact this are probably in most cases some inflection point no maximums. But since (to) many variables are needed to change muon percentage (in plus), it looks like maximums. > Everyone huddles around what's the best design at that moment, regardless of the long term consequences. > It's one reason I convinced Stephen to run the samplefile only once a week, as it will help give some diversity, without everyone suddenly being distracted by the latest, best design like a 5yo with ADHD. Now I'm confused what you really want form this project. Best design, detailed search space cover to search strange solutions. But no matter you want, current search method (including my fork), or rather it implementation is far from perfect. You know, I don't like current comparing S0 (seed 0 result)' result with AVG (average result from 5 seeds) - it can miss better design if S0 is below AVG, or do to many no necessary recheck if S0 it above AVG. My idea also isn't perfect. It doesn't suffer to above illness, but since correlation with results from different seeds is weak, it most of time run 5 separate optimizations. Quite often when one seed improve others go down. And almost always doesn't improve. See statistics in previous post. After my experiment, I think the worst problem is wrong designs scoring method. Now designs with quite different possibilities to improve itself have same scoring. I.e. take best (4%) and bad (0.5%) design and make last solenoid in them very narrow. Now both of them will have probably very similar low score, but chance to improve quite quite different. IMHO scoring should be separated form muon percentage at the end, and be something totally different. My proposal is 1/3 muon% with designated energy at the end, 1/3 total muon% at the end, 1/3 Mpts (or total muon percentage at some points - i.e. begin of solenoid group). IMHO it is bigger change to optimize solenoids that have some particles going through them than mostly unused. And what is more important - changes in designs will have effects in score - so we have something to optimize! And at the end some general optimization ideas 1. Partial result save. Quite often design are very similar so we can reuse computations done in earlier simulations to speedup current one. I.e. if we save latest (or best) 10 runs at points before solenoid group change - we can reuse it if current genome is identical to this point with saved one. Even if it take hundreds of MB drive space, this is not problem with current hard drives. This should give significant gain. 2. Don't count particles with negative x. This give little gain - buy it always something. > I know you're focused more on recheck rates (or rather, full runs, rather than 1/5th runs) but we're worried about design optomisation as that's by far and away the most important. No offence, but I have impression you are focused to keep current client at all cost. And get rid off stupid troll (read me) with possible little effort and without telling why my proposal are bad. PS. I hope my ideas was AT LAST understandable. I want REALLY improve project, not only argue with you to make you irritated. |
| K`Tetch 2012-05-23 01:59:55 | Again, you're looking at things the wrong way. Muon1 is not an arbitary project, a game where the point is to get the best score. It's a distributed project to design the best accelerator, most accurately. The overriding concern is accuracy, NOT raising the score as fast as possible. Some of your suggestions make sense, only if you ignore the physics, such as your 'partial results save', which can't be done, because we're talking about statistical particle decay (pions to muons) which isn't always repeatable. In doing the 'best designs' videos, I've rerun designs from over 40 lattices, and there's been a grand total of ONE that's had an identical result (and cross version, it's been even worse) My focus is not on trying to keep the current client at all costs, but to try and keep the client as accurate from a physics perspective as possible. To me, 'best score' is not as important as the data from complete simulations, but it's an aim. And yes, I know the method to find the best design is bad right now, that's why we're doing this lattice, to see what we have running client-solo. You see the two charts above, that's the difference in the samplefiles, now if we can make it work collaboratively like the second chart, but with the diversity of the first. Now, you're talking about S0 and the problems of it being just above, or just below AVG. However, if that's the case, then it's not a significant improvement or loss on the best so far, so it's not a loss (and you can't tell the S0 thats abnormally high compared to the AVG and causing a 5-run needlessly, over one that's abnormally low and not trigging a 5-run. If we could make that determination at the start, we wouldn't NEED the 5-run. |
| Hannibal 2012-05-23 06:15:10 | Maybe i'm wrong, but seed X - mean for me pseudo number generator seed - so pion to muon decay will be identical i each simulation using same seed. In your reruns you have different results because previous clients using random seeds (here I can be wrong again). So save is possible. And IMHO you are looking at tings wrong way. During search phase computations should be simplified as much as possible. Only very best results should be rechecked in 100% accurate scientific method. It REALLY shouldn't matter how you get best design - you accepts manual desing - so you can treat this less scientific approach in same way. And about endlessly recheck. If you see i.e. 5 times score 3.13642 and after recheck it always worse, and see this 3.13642 again you are ALMOST sure this will be worse again. At last some heuristics should block recheck in this situations. And about diversity - remember clients and give them different samplefiles. |
| tomaz 2012-05-23 13:26:28 | Hannibal, I see your point. I think you should run your experiment on few best so far designs on a given lattice, not from the very begining (random seed). It might prove your point better. |
| Hannibal 2012-05-24 06:03:20 | Tomaz, I can do it, but only if K`Tetch and Stephen will be interested with its results. Otherwise, this will be waste of my and my computer time. |
| Hannibal 2012-07-30 17:53:41 | It's time to end my "little" experiment, and make some summary. I've run 40079 individual simulations (4 490 852.8 Mpts), and 492 of them are rechecked. Best of each seed are: 0.930942 0.908378 0.949473 0.947420 0.928567, an the best average is 0.932956. Std. deviation of "AVG - seedX" are: 0.021405 0.021246 0.037192 0.023686 0.018125 - so best behave seed 4. And my conclusions. Overall score are not impressed, however because it is "single" experiment this can be statistical deviation, it is hard to say if my method is better or worse (overall). But after so many runs, it's cleanly for me that scoring method is far from perfect, and should promote heavier "more Mpts" designs. This also include new design creating algorithm. Despite bigger genotype base base, recovery from local minimum takes thousands of simulations - scoring method is IMHO one to blame. Results from each seed are quite often very different. Mostly one (or at most two) are much different than other 4 (or 3). This confirms that using "average" with compare of "seed 0" is bad, and can either miss better design, or endless and pointless recheck. I've difficulties with express my thoughts in English, so better you analyze my data by yourself. If you want get any of my data please write to "hannibal AT astral D0T lodz D0T pl". I can you provide each seed individual config and results.dat, my external management program source and its logs and my simple statistical analyses in libreoffice calc format (links in one of my previous post are not longer valid). PS. I don't expect any replies. EOT |