 |
| abyzz 2005-11-10 04:20:48 | Any way to make muon1 explore the dark areas in yield plots ? BR Abyss |
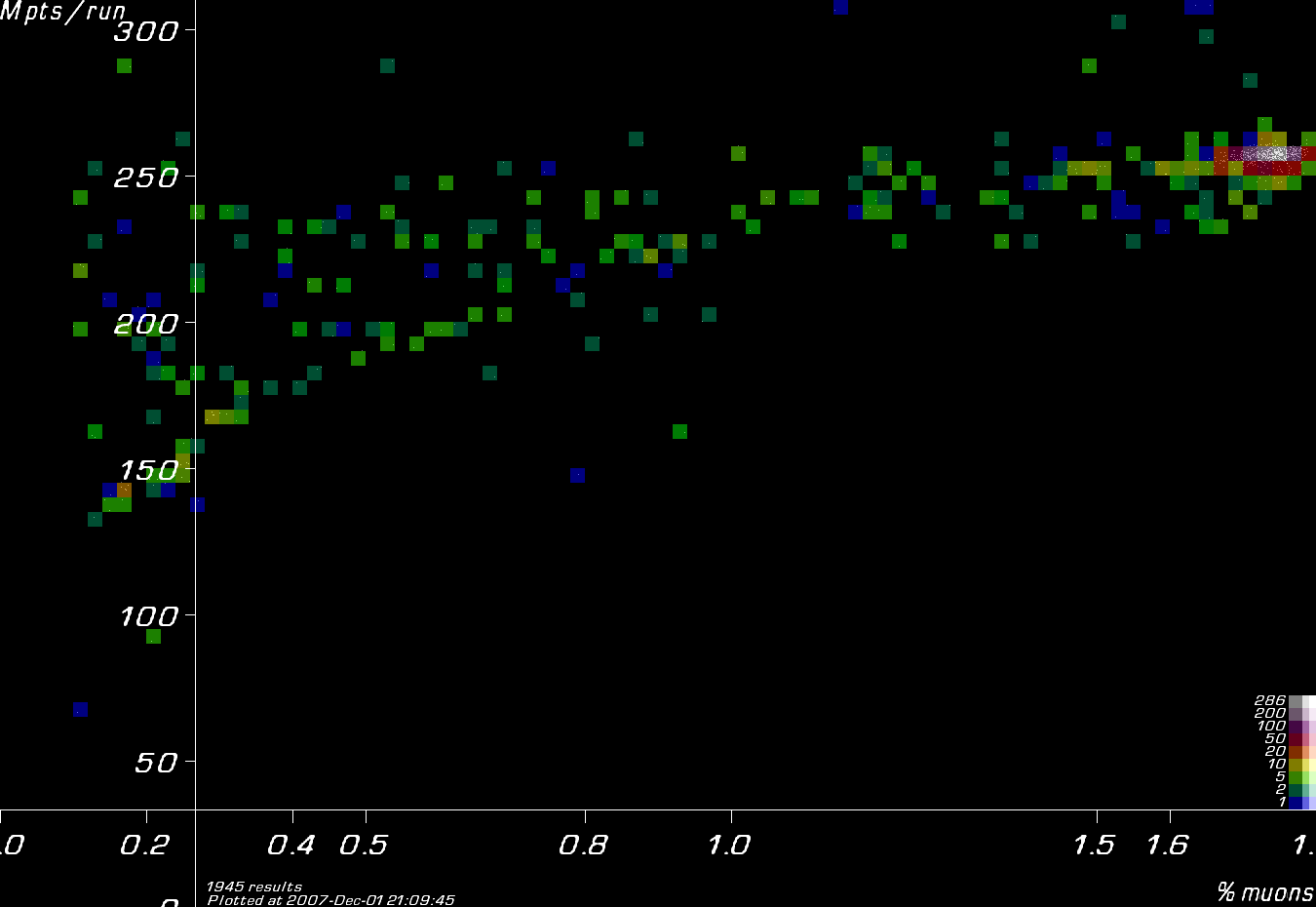
| Stephen Brooks 2005-11-11 03:27:25 | Those plots are only a "projection" so don't really give a good idea of the space. Although there *are* large gaps where there aren't many results. However, that's usually because the designs in those areas aren't as good. Increasing the number of 'random' trialtypes will make your Muon program explore more territory, but the problem is that it is completely random, so it will always find really bad designs. The fruitful attempts will come from exploring the edges of the current high-yield regions. The current Muon1 algorithm tries to do that, by either varying just a few parameters or moving between two good results. Having said that, it's not at all perfect and there's some scope either for me to upgrade it (for which I have a few ideas) or for someone else to manually do an analysis and make a script to submit designs in their area of interest to queue.txt. Ideas I've had related to this include: - There's another sort of 'plot' that shows pure design-space in a geometrically more accurate way; I fully intended to use *that* for the optimisation status graphs, but then you asked for more of the old plots, so I put those up anyway since they were easier to do. I might make an upgrade or do both at some stage. - It's possible I could make special samplefiles only from a certain pixel in those plots. PhaseRotC_bigS1 is particularly nice example where one can see several 'lumps' forming as the optimisation progresses. - For the newer sort of visualisation, it could be informative to just take the "core" of high-yield results and look at that (a sort of zoomed-in version). - Analysing that region reveals the parameters that can be varied without completely messing up the yield; an 'intelligent random' trialtype that uses that information is the sort of thing I would include in a version of Muon1 if I upgraded the optimiser. Another good way of exploring territory away from the main cluster is to switch sample files off and either start from nothing at all, or some unusual result half-way up that you think might produce a promising branch. This is good because it's not stupid like the 'random' trialtype: it just goes up an independent way. As an example of this, here is a picture of the more advanced visualisation applied to one of [TA]z's files from a while ago:-  The white area is the highest yield and corresponds to what the rest of the network was doing. Those other green "wings" down near the bottom were several independent computers that he had set up over several months. The blue fuzzy ball of low-yield between them is from pure random trial types, so you can see how the different paths have grown out of that ball and started going in different directions, but also generally in the "upward" direction towards the top yields. |
| abyzz 2005-11-11 05:37:33 | Thanks a lot for the explanation - I'll start exploring. |
| abyzz 2005-12-02 00:04:06 | Hi, can you spot any significant changes on PhaseRotB and ChicaneLinacB ? I have 3 3Ghz P4's crunching away on these two lattices with no samplefile updates. BR Abyss |



{kind=link}